Introduction
Nagios can be configured to support distributed monitoring of network services and resources. I'll try to briefly explan how this can be accomplished...
Goals
The goal in the distributed monitoring environment that I will describe is to offload the overhead (CPU usage, etc.) of performing service checks from a "central" server onto one or more "distributed" servers. Most small to medium sized shops will not have a real need for setting up such an environment. However, when you want to start monitoring hundreds or even thousands of hosts (and several times that many services) using Nagios, this becomes quite important.
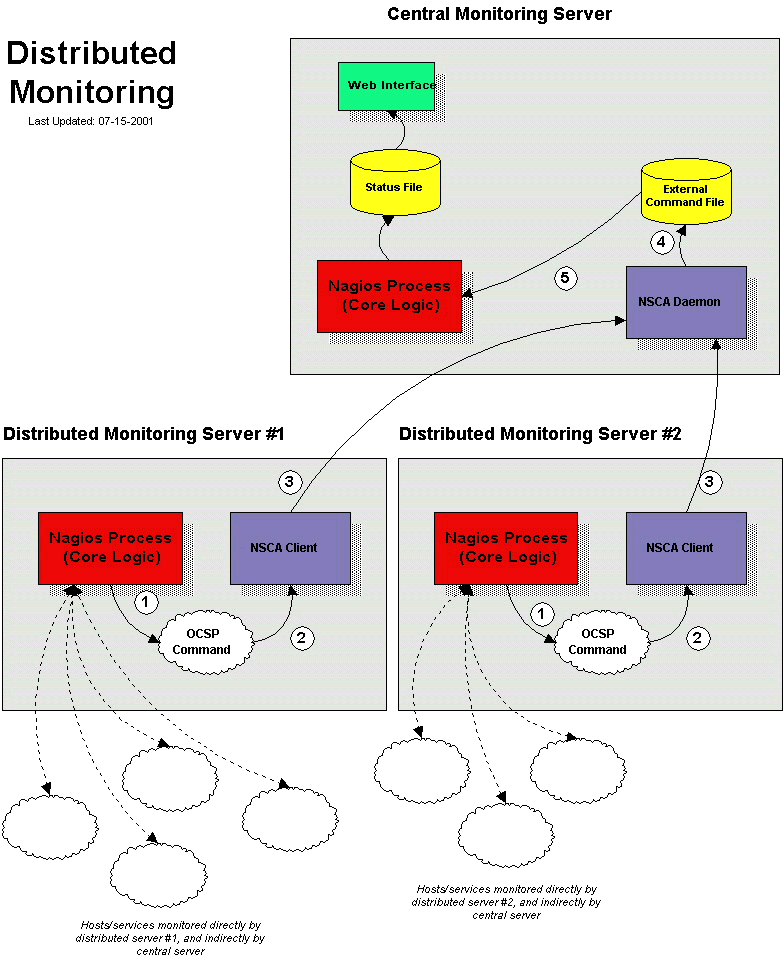
Reference Diagram
The diagram below should help give you a general idea of how distributed monitoring works with Nagios. I'll be referring to the items shown in the diagram as I explain things...
Central Server vs. Distributed Servers
When setting up a distributed monitoring environment with Nagios, there are differences in the way the central and distributed servers are configured. I'll show you how to configure both types of servers and explain what effects the changes being made have on the overall monitoring. For starters, lets describe the purpose of the different types of servers...
The function of a distributed server is to actively perform checks all the services you define for a "cluster" of hosts. I use the term "cluster" loosely - it basically just mean an arbitrary group of hosts on your network. Depending on your network layout, you may have several cluters at one physical location, or each cluster may be separated by a WAN, its own firewall, etc. The important thing to remember to that for each cluster of hosts (however you define that), there is one distributed server that runs Nagios and monitors the services on the hosts in the cluster. A distributed server is usually a bare-bones installation of Nagios. It doesn't have to have the web interface installed, send out notifications, run event handler scripts, or do anything other than execute service checks if you don't want it to. More detailed information on configuring a distributed server comes later...
The purpose of the central server is to simply listen for service check results from one or more distributed servers. Even though services are occassionally actively checked from the central server, the active checks are only performed in dire circumstances, so lets just say that the central server only accepts passive check for now. Since the central server is obtaining passive service check results from one or more distributed servers, it serves as the focal point for all monitoring logic (i.e. it sends out notifications, runs event handler scripts, determines host states, has the web interface installed, etc).
Obtaining Service Check Information From Distributed Monitors
Okay, before we go jumping into configuration detail we need to know how to send the service check results from the distributed servers to the central server. I've already discussed how to submit passive check results to Nagios from same host that Nagios is running on (as described in the documentation on passive checks), but I haven't given any info on how to submit passive check results from other hosts.
In order to facilitate the submission of passive check results to a remote host, I've written the nsca addon. The addon consists of two pieces. The first is a client program (send_nsca) which is run from a remote host and is used to send the service check results to another server. The second piece is the nsca daemon (nsca) which either runs as a standalone daemon or under inetd and listens for connections from client programs. Upon receiving service check information from a client, the daemon will sumbit the check information to Nagios (on the central server) by inserting a PROCESS_SVC_CHECK_RESULT command into the external command file, along with the check results. The next time Nagios checks for external commands, it will find the passive service check information that was sent from the distributed server and process it. Easy, huh?
Distributed Server Configuration
So how exactly is Nagios configured on a distributed server? Basically, its just a bare-bones installation. You don't need to install the web interface or have notifications sent out from the server, as this will all be handled by the central server.
Key configuration changes:
In order to make everything come together and work properly, we want the distributed server to report the results of all service checks to Nagios. We could use event handlers to report changes in the state of a service, but that just doesn't cut it. In order to force the distributed server to report all service check results, you must enabled the obsess_over_services option in the main configuration file and provide a ocsp_command to be run after every service check. We will use the ocsp command to send the results of all service checks to the central server, making use of the send_nsca client and nsca daemon (as described above) to handle the tranmission.
In order to accomplish this, you'll need to define an ocsp command like this:
ocsp_command=submit_check_result
The command definition for the submit_check_result command looks something like this:
define command{
command_name submit_check_result
command_line /usr/local/nagios/libexec/eventhandlers/submit_check_result $HOSTNAME$ '$SERVICEDESC$' $SERVICESTATE$ '$OUTPUT$'
}
The submit_check_result shell scripts looks something like this (replace central_server with the IP address of the central server):
#!/bin/sh
# Arguments:
# $1 = host_name (Short name of host that the service is
# associated with)
# $2 = svc_description (Description of the service)
# $3 = state_string (A string representing the status of
# the given service - "OK", "WARNING", "CRITICAL"
# or "UNKNOWN")
# $4 = plugin_output (A text string that should be used
# as the plugin output for the service checks)
#
# Convert the state string to the corresponding return code
return_code=-1
case "$3" in
OK)
return_code=0
;;
WARNING)
return_code=1
;;
CRITICAL)
return_code=2
;;
UNKNOWN)
return_code=-1
;;
esac
# pipe the service check info into the send_nsca program, which
# in turn transmits the data to the nsca daemon on the central
# monitoring server
/bin/echo -e "$1\t$2\t$return_code\t$4\n" | /usr/local/nagios/bin/send_nsca central_server -c /usr/local/nagios/etc/send_nsca.cfg
The script above assumes that you have the send_nsca program and it configuration file (send_nsca.cfg) located in the /usr/local/nagios/bin/ and /usr/local/nagios/etc/ directories, respectively.
That's it! We've sucessfully configured a remote host running Nagios to act as a distributed monitoring server. Let's go over exactly what happens with the distributed server and how it sends service check results to Nagios (the steps outlined below correspond to the numbers in the reference diagram above):
Central Server Configuration
We've looked at hot distributed monitoring servers should be configured, so let's turn to the central server. For all intensive purposes, the central is configured as you would normally configure a standalone server. It is setup as follows:
There are three other very important things that you need to keep in mind when configuring the central server:
It is important that you either disable all service checks on a program-wide basis or disable the enable_active_checks option in the definitions for each service that is monitored by a distributed server. This will ensure that active service checks are never executed under normal circumstances. The services will keep getting rescheduled at their normal check intervals (3 minutes, 5 minutes, etc...), but the won't actually be executed. This rescheduling loop will just continue all the while Nagios is running. I'll explain why this is done in a bit...
That's it! Easy, huh?
Problems With Passive Checks
For all intensive purposes we can say that the central server is relying solely on passive checks for monitoring. The main problem with relying completely on passive checks for monitoring is the fact that Nagios must rely on something else to provide the monitoring data. What if the remote host that is sending in passive check results goes down or becomes unreachable? If Nagios isn't actively checking the services on the host, how will it know that there is a problem?
Fortunately, there is a way we can handle these types of problems...
Freshness Checking
Nagios supports a feature that does "freshness" checking on the results of service checks. More information freshness checking can be found here. This features gives some protection against situations where remote hosts may stop sending passive service checks into the central monitoring server. The purpose of "freshness" checking is to ensure that service checks are either being provided passively by distributed servers on a regular basis or performed actively by the central server if the need arises. If the service check results provided by the distributed servers get "stale", Nagios can be configured to force active checks of the service from the central monitoring host.
So how do you do this? On the central monitoring server you need to configure services that are being monitoring by distributed servers as follows...
Nagios periodically checks the "freshness" of the results for all services that have freshness checking enabled. The freshness_threshold option in each service definition is used to determine how "fresh" the results for each service should be. For example, if you set this value to 5 for one of your services and your interval_length directive is set to 60 seconds, Nagios will consider the service results to be "stale" if they're older than 5 minutes. If you do not specify a value for the freshness_threshold option, Nagios will automatically calculate a "freshness" threshold by looking at either the normal_check_interval or retry_check_interval options (depending on what type of state the service is in). If the service results are found to be "stale", Nagios will run the service check command specified by the check_command option in the service definition, thereby actively checking the service.
Remember that you have to specify a check_command option in the service definitions that can be used to actively check the status of the service from the central monitoring server. Under normal circumstances, this check command is never executed (because active checks were disabled on a program-wide basis or for the specific services). When freshness checking is enabled, Nagios will run this command to actively check the status of the service even if active checks are disabled on a program-wide or service-specific basis.
If you are unable to define commands to actively check a service from the central monitoring host (or if turns out to be a major pain), you could simply define all your services with the check_command option set to run a dummy script that returns a critical status. Here's an example... Let's assume you define a command called 'service-is-stale' and use that command name in the check_command option of your services. Here's what the definition would look like...
define command{
command_name service-is-stale
command_line /usr/local/nagios/libexec/staleservice.sh
}
The staleservice.sh script in your /usr/local/nagios/libexec directory might look something like this:
#!/bin/sh /bin/echo "CRITICAL: Service results are stale!" exit 2 |
When Nagios detects that the service results are stale and runs the service-is-stale command, the /usr/local/nagios/libexec/staleservice.sh script is executed and the service will go into a critical state. This would likely cause notifications to be sent out, so you'll know that there's a problem.
Performing Host Checks
At this point you know how to obtain service check results passivly from distributed servers. This means that the central server is not actively checking services on its own. But what about host checks? You still need to do them, so how?
Since host checks usually compromise a small part of monitoring activity (they aren't done unless absolutely necessary), I'd recommend that you perform host checks actively from the central server. That means that you define host checks on the central server the same way that you do on the distributed servers (and the same way you would in a normal, non-distributed setup).
There are ways to obtain host checks passively, but implementing them is beyond the scope of what I care to write about at this time. :-)